Boosting Probabilistic Graphical Model Inference by Incorporating Prior Knowledge from Multiple Sources
Inferring regulatory networks from experimental data via probabilistic graphical models is a popular framework to gain insights into biological systems. However, the inherent noise in experimental data coupled with a …
Oluwasegun Odesola May 16, 2026 1 views 0 reactions
18/20
4Us Score
Problem Description
Inferring regulatory networks from experimental data via probabilistic graphical models is a popular framework to gain insights into biological systems. However, the inherent noise in experimental data coupled with a limited sample size reduces the performance of network reverse engineering. High throughput data like microarray is very high dimensional coupled with a typical low number of replicates and noisy measurements. Reverse engineering of regulatory network on the basis of such data is hence challenging and often fails to reach the desired level of accuracy.
Context
Probabilistic graphical models, like (Dynamic) Bayesian Networks and Gaussian Graphical Models, have turned out to be useful for extracting meaningful biological insights from experimental data in life science research. These models can infer features of cellular networks in a data driven manner. However, network inference from experimental data is challenging because of the typical low signal to noise ratio. To deal with this problem one can either work at experimental level by increasing the sample size, which is practically difficult, or at the inference level by embedding biological background knowledge.
Target Audience
life science researchers working with experimental data and network inference
18/20
4Us Score
⏳ Pending
Validation
AI & ML
Category
4Us Problem Worthiness Score
1️⃣ Unworkable
4/5
80%
The paper addresses a fundamental technical challenge where high throughput data like microarray is very high dimensional coupled with a typical low number of replicates and noisy measurements. Reverse engineering of regulatory network on the basis of such data is hence challenging and often fails to reach the desired level of accuracy. The inherent noise in experimental data coupled with a limited sample size reduces the performance of network reverse engineering.
Integrating known information from databases and biological literature as prior knowledge thus appears to be beneficial. However, biological knowledge covers many different aspects and is widely distributed across multiple knowledge resources, such as pathway databases, Gene Ontology and others. Hence, integrating this heterogenous information into the learning process is not straight forward.
Prior knowledge from existing sources of biological information can address this low signal to noise problem by biasing the network inference towards biologically plausible network structures. Although integrating various sources of information is desirable, their heterogeneous nature makes this task challenging.
In the past most authors have concentrated on integrating one particular information resource into the learning process. The focus of this paper is on construction of consensus priors from multiple, heterogenous knowledge sources. We are at this point aware of the fact that there is a broad literature on (probabilistic) data integration, which goes beyond our specific question and covers a large variety of different aspects.
Total Score: 18/20
(90% on rubric scale)
— Decision:
✅ ACCEPT - Problem worth solving
Evidence Quality
7.0/10
⭐ Tier 1: 5📊 Tier 2: 0📄 Tier 3: 0💬 Tier 4: 0
Methodology
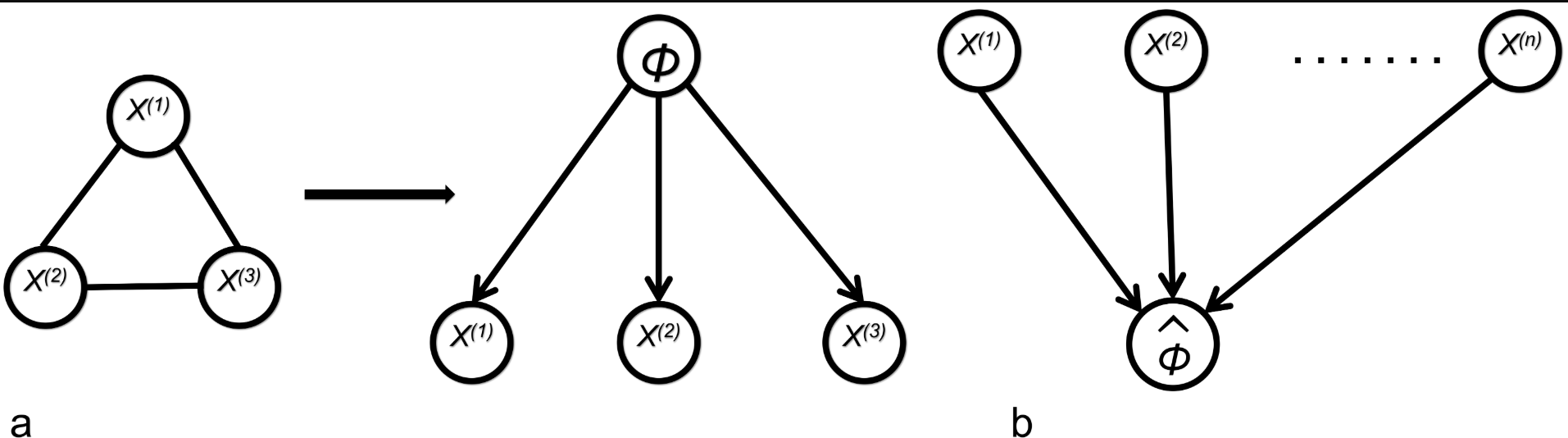
We propose two computational methods to incorporate various information sources into a probabilistic consensus structure prior to be used in graphical model inference. Our first model, called Latent Factor Model (LFM), assumes a high degree of correlation among external information sources and reconstructs a hidden variable as a common source in a Bayesian manner. The second model, a Noisy-OR, picks up the strongest support for an interaction among information sources in a probabilistic fashion. The Latent Factor Model is based on the idea that the prior information encoded in matrices X(1), X(2), ... ,X(n) all originate from the true but unknown network W. We use this notion to conduct joint Bayesian inference on W as well as additional parameters. The Noisy-OR represents a non-deterministic disjunctive relation between an effect and its possible causes.
Technologies Used
Bayesian NetworksGaussian Graphical ModelsMarkov Chain Monte Carlo (MCMC)Beta distributionsLatent Factor ModelNoisy-OR
Dataset
We used KEGG signaling pathways converted into graphs via the R-package KEGGgraph, GO annotation, PathwayCommons, KEGG, protein domain annotation (InterPro), protein domain interactions (DOMINE), STRING database, breast cancer microarray data by van't Veer et al. consisting of 1214 genes for 98 patient samples, and yeast heat-shock response microarray data from GEO (GSE3316) containing 12 samples.
Methodology Diagram
591ed707_Screenshot_2026-05-16_165542.png
Resources & Links
Results & Findings
Our extensive computational studies on KEGG signaling pathways as well as on gene expression data from breast cancer and yeast heat shock response reveal that both approaches can significantly enhance the reconstruction accuracy of Bayesian Networks compared to other competing methods as well as to the situation without any prior. The results showed a clear positive effect of our priors for biologically relevant sample sizes. Specifically for sample sizes between 20 and 100 LFM, NOM and NOM.RNK were superior to all other methods. With the NOM and NOM.RNK priors more than 60% of the inferred edges could be explained by the literature and around 30% of the literature known paths corresponded to pathways in the inferred network.
Key Findings
['Both LFM and NOM approaches can significantly enhance the reconstruction accuracy of Bayesian Networks compared to other competing methods', 'More than 60% of the inferred edges using NOM and NOM.RNK priors could be explained by literature', 'The methods showed clear advantage over STRING database in terms of higher optimal balanced accuracy', 'LFM particularly worked well if networks were not too small', 'The automatic weighting of sources provided by the LFM method was able to filter out irrelevant/noisy information']
Limitations
The reason for the bad performance of LFM is probably the low number of available knowledge sources combined with a relatively small network size. Therefore, in case of very small networks and/or sparse prior knowledge NOM appears to be a more robust choice. Moreover, NOM is clearly the computationally cheaper approach and thus should be favored for very large (e.g. genome-scale) networks.
Validation Status
Current Status
Human Review Pending
Method Selected:👤 Human Only (Traditional)
What this means
👀 A human expert is currently evaluating this project
📅 Review typically completes within 1-3 business days
No comments yet. Be the first to share your thoughts!
S
Oluwasegun Odesola
@segreen
I'm a researcher and data scientist at the intersection of artificial intelligence, algorithmic fairness, Financial and educational technology, with a …
Discussion (0)
No comments yet. Be the first to share your thoughts!